ChatGPT技術(shù)報告
發(fā)表時間:2023-04-10
ChatGPT是一個由OpenAI開發(fā)的大型語言模型,是GPT(Generative Pretrained Transformer)系列模型的一部分。它使用了 Transformer 架構(gòu),并在大量的文本數(shù)據(jù)上進行了預(yù)訓(xùn)練。預(yù)訓(xùn)練的目的是使模型能夠從大量的文本中學(xué)習(xí)語言知識和模式,從而在接下來的任務(wù)中更好地進行語言生成。ChatGPT 的應(yīng)用領(lǐng)域廣泛,包括聊天機器人,問答系統(tǒng),文本生成,語音識別等。在聊天機器人領(lǐng)域,ChatGPT可以提供人類般的自然語言回答,并且在語法和語義方面的表現(xiàn)十分出色。
一、GPT發(fā)展歷程
Generative Pre-trained Transformer (GPT),是一種基于互聯(lián)網(wǎng)可用數(shù)據(jù)訓(xùn)練的文本生成深度學(xué)習(xí)模型。它用于問答、文本摘要生成、機器翻譯、分類、代碼生成和對話 AI。
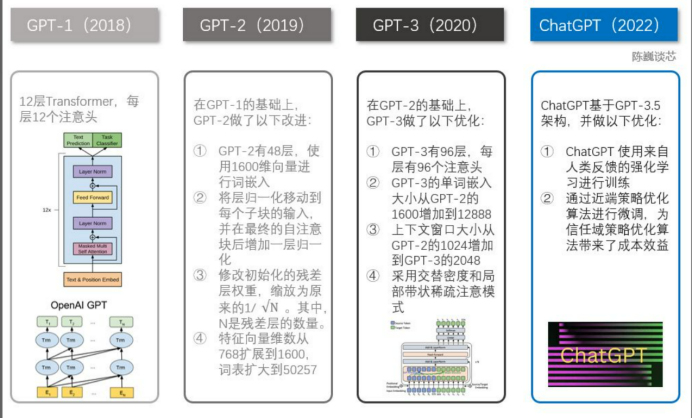
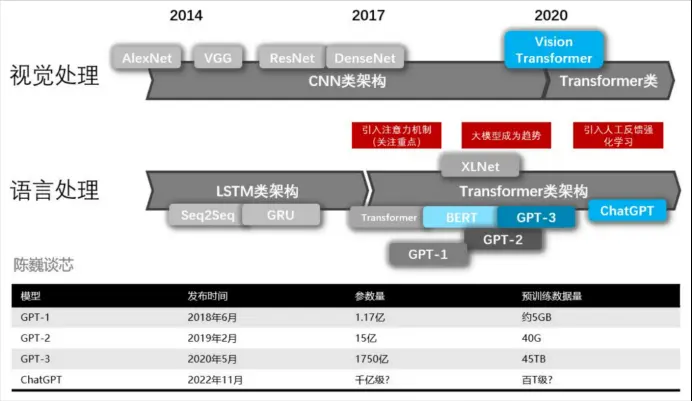
1.GPT-1
2018 年,GPT-1 誕生,這一年也是 NLP(自然語言處理)的預(yù)訓(xùn)練模型元年。性能方面,GPT-1 有著一定的泛化能力,能夠用于和監(jiān)督任務(wù)無關(guān)的 NLP 任務(wù)中。其常用任務(wù)包括:
◇ 自然語言推理:判斷兩個句子的關(guān)系(包含、矛盾、中立)
◇ 問答與常識推理:輸入文章及若干答案,輸出答案的準(zhǔn)確率
◇ 語義相似度識別:判斷兩個句子語義是否相關(guān)
◇ 分類:判斷輸入文本是指定的哪個類別
雖然 GPT-1 在未經(jīng)調(diào)試的任務(wù)上有一些效果,但其泛化能力遠(yuǎn)低于經(jīng)過微調(diào)的有監(jiān)督任務(wù),因此 GPT-1 只能算得上一個還算不錯的語言理解工具而非對話式 AI。
2.GPT-2
GPT-2 也于 2019 年如期而至,不過,GPT-2 并沒有對原有的網(wǎng)絡(luò)進行過多的結(jié)構(gòu)創(chuàng)新與設(shè)計,只使用了更多的網(wǎng)絡(luò)參數(shù)與更大的數(shù)據(jù)集:最大模型共計 48 層,參數(shù)量達 15 億,學(xué)習(xí)目標(biāo)則使用無監(jiān)督預(yù)訓(xùn)練模型做有監(jiān)督任務(wù)。在性能方面,除了理解能力外,GPT-2 在生成方面第一次表現(xiàn)出了強大的天賦:閱讀摘要、聊天、續(xù)寫、編故事,甚至生成假新聞、釣魚郵件或在網(wǎng)上進行角色扮演通通不在話下。在“變得更大”之后,GPT-2 的確展現(xiàn)出了普適而強大的能力,并在多個特定的語言建模任務(wù)上實現(xiàn)了彼時的最佳性能。
3.GPT-3
之后,GPT-3 出現(xiàn)了,作為一個無監(jiān)督模型,幾乎可以完成自然語言處理的絕大部分任務(wù),例如面向問題的搜索、閱讀理解、語義推斷、機器翻譯、文章生成和自動問答等等。而且,該模型在諸多任務(wù)上表現(xiàn)卓越,例如在法語-英語和德語-英語機器翻譯任務(wù)上達到當(dāng)前最佳水平,自動產(chǎn)生的文章幾乎讓人無法辨別出自人還是機器,更令人驚訝的是在兩位數(shù)的加減運算任務(wù)上達到幾乎 100% 的正確率,甚至還可以依據(jù)任務(wù)描述自動生成代碼。一個無監(jiān)督模型功能多效果好,似乎讓人們看到了通用人工智能的希望,這就是 GPT-3 影響如此之大的主要原因。
InstructGPT 的工作原理是開發(fā)人員通過結(jié)合監(jiān)督學(xué)習(xí)+從人類反饋中獲得的強化學(xué)習(xí)。來提高 GPT-3 的輸出質(zhì)量。在這種學(xué)習(xí)中,人類對模型的潛在輸出進行排序;強化學(xué)習(xí)算法則對產(chǎn)生類似于高級輸出材料的模型進行獎勵。開發(fā)人員將提示分為三個部分,并以不同的方式為每個部分創(chuàng)建響應(yīng):人類作家會對第一組提示做出響應(yīng)。開發(fā)人員微調(diào)了一個經(jīng)過訓(xùn)練的 GPT-3 ,將它變成 InstructGPT 以生成每個提示的現(xiàn)有響應(yīng)。
下一步是訓(xùn)練一個模型,使其對更好的響應(yīng)做出更高的獎勵。對于第二組提示,經(jīng)過優(yōu)化的模型會生成多個響應(yīng)。人工評分者會對每個回復(fù)進行排名。在給出一個提示和兩個響應(yīng)后,一個獎勵模型(另一個預(yù)先訓(xùn)練的 GPT-3)學(xué)會了為評分高的響應(yīng)計算更高的獎勵,為評分低的回答計算更低的獎勵。
開發(fā)人員使用第三組提示和強化學(xué)習(xí)方法近端策略優(yōu)化(Proximal Policy Optimization, PPO)進一步微調(diào)了語言模型。給出提示后,語言模型會生成響應(yīng),而獎勵模型會給予相應(yīng)獎勵。PPO 使用獎勵來更新語言模型。
二、ChatGPT的技術(shù)原理
總體來說,Chatgpt 和 InstructGPT 一樣,是使用 RLHF(從人類反饋中強化學(xué)習(xí))訓(xùn)練的。不同之處在于數(shù)據(jù)是如何設(shè)置用于訓(xùn)練(以及收集)的。
ChatGPT是一個大型語言模型,由OpenAI訓(xùn)練,具有高效的語言處理能力。它的底層原理主要包括三個方面:Transformer架構(gòu)、自注意力機制和預(yù)訓(xùn)練。
(1) Transformer架構(gòu):Transformer是一種用于處理序列數(shù)據(jù)(如文本)的神經(jīng)網(wǎng)絡(luò)架構(gòu),是在自注意力機制的基礎(chǔ)上構(gòu)建的。編碼器和解碼器是它的兩個主要組成部分,分別用于處理輸入數(shù)據(jù)和生成輸出數(shù)據(jù)。
(2) 自注意力機制:自注意力機制是Transformer架構(gòu)的核心,它通過編碼輸入單元并計算每個輸入單元與每個輸出單元的相關(guān)性,來實現(xiàn)對輸入數(shù)據(jù)的分析。
(3) 預(yù)訓(xùn)練:預(yù)訓(xùn)練是一個在大量文本數(shù)據(jù)上訓(xùn)練語言模型的過程。通過預(yù)測文本中下一個詞語的概率,模型學(xué)習(xí)語言的語法、語義和模式。預(yù)訓(xùn)練后的模型可以在新的數(shù)據(jù)上獲得更好的表現(xiàn)。
ChatGPT的訓(xùn)練過程分為以下三個階段:
第一階段:訓(xùn)練監(jiān)督策略模型
GPT3.5本身很難理解人類不同類型指令中蘊含的不同意圖,也很難判斷生成內(nèi)容是否是高質(zhì)量的結(jié)果。為了讓GPT3.5初步具備理解指令的意圖,首先會在數(shù)據(jù)集中隨機抽取問題,由人類標(biāo)注人員,給出高質(zhì)量答案,然后用這些人工標(biāo)注好的數(shù)據(jù)來微調(diào)GPT-3.5模型(獲得SFT模型,Supervised Fine-Tuning) 。此時的SFT模型在遵循指令/對話方面已經(jīng)優(yōu)于GPT-3,但不一定符合人類偏好。
第二階段:訓(xùn)練獎勵模型(Reward Mode,RM)
這個階段的主要是通過人工標(biāo)注訓(xùn)練數(shù)據(jù)(約33K個數(shù)據(jù)),來訓(xùn)練回報模型。在數(shù)據(jù)集中隨機抽取問題,使用第一階段生成的模型,對于每個問題,生成多個不同的回答。人類標(biāo)注者對這些結(jié)果綜合考慮給出排名順序。這一過程類似于教練或老師輔導(dǎo)。
接下來,使用這個排序結(jié)果數(shù)據(jù)來訓(xùn)練獎勵模型。對多個排序結(jié)果,兩兩組合,形成多個訓(xùn)練數(shù)據(jù)對RM模型接受一個輸入,給出評價回答質(zhì)量的分?jǐn)?shù)。這樣,對于一對訓(xùn)練數(shù)據(jù),調(diào)節(jié)參數(shù)使得高質(zhì)量回答的打分比低質(zhì)量的打分要高。
第三階段:采用PPO(Proximal Policy Optimization,近端策略優(yōu)化)強化學(xué)習(xí)來優(yōu)化策略。
PPO的核心思路在于將Policy Gradient中On-policy的訓(xùn)練過程轉(zhuǎn)化為Off-policy,即將在線學(xué)習(xí)轉(zhuǎn)化為離線學(xué)習(xí),這個轉(zhuǎn)化過程被稱之為lmportance Sampling。這一階段利用第二階段訓(xùn)練好的獎勵模型,靠獎勵打分來更新預(yù)訓(xùn)練模型參數(shù)。在數(shù)據(jù)集中隨機抽取問題,使用PPO模型生成回答,并用上一階段訓(xùn)練好的RM模型給出質(zhì)量分?jǐn)?shù)。把回報分?jǐn)?shù)依次傳遞,由此產(chǎn)生策略梯度,通過強化學(xué)習(xí)的方式以更新PPO模型參數(shù)。

